Aim
The aim of this project is to develop a sentiment analysis model that classifies a tweet as having a positive or a
negative sentiment. While implementing this sentiment analysis model, I explore different Deep Learning models such as
1-D Convolutional Neural Networks (CNN) and Recurrent Neural Networks (RNN). In this project, I compare the performance
of the Deep Learning models with Machine Learning techniques such as Logistic Regression and Random Forest Classifier.
Implementation
- Data Exploration
-
Twitter Sentiment Extraction
This is an open dataset provided for the Twitter Sentiment Extraction competition on Kaggle. The dataset contains around 30000 text-to-sentiment mappings. Running various models on the dataset yielded a maximum accuracy of around 68%. Upon analysis, under-fitting of data was observed due to insufficient data points. -
Sentiment140 dataset
This dataset is an extended version of the previous Twitter dataset, containing 1.6 million tweets using the Twitter API. The tweet texts are classified using positive and negative labels along with other tweet-specific fields. -
Twitter Sentiment Analysis dataset
This is an entity-level sentiment analysis dataset of Twitter. The dataset contains around 75000 text-to-sentiment. This dataset also encountered similar issues as the first dataset i.e. under-fitting due to the small dataset size.
To get a more generalized and sufficiently large dataset, all the above three datasets were combined with each datapoint/tweet having either a positive or negative label.
- Data Preprocessing
-
Data cleaning
First, I processed the data to remove non-contributing data/words such as stop words, URLs, emojis, and punctuation. To ignore the usernames mentioned in the tweet, I converted any text preceded by a @ to @user. Finally, I ensured all the text was also converted to a lowercase to make the data more uniform. -
Continuous letters
Many tweets consisted of text containing characters repeating more than 2 times. (e.g. goooooood). This was causing the model to treat goooooood and good as two different words despite meaning the same thing. To avoid such cases, I modified the data to only include at most 2 continuous letters i.e. goooooood was now treated as good. This reduced the overall number of distinct words in the vocabulary. -
Standardizing tweet length
To standardize the input, I padded all the tweets to have the same length before converting the tweets into embeddings. The tweets were padded equally on both sides with 0s to have a uniform length of 64 words. Any tweets of initial length less than 3 were discarded.
- Model Exploration
In this step, I compare the performance of various Deep Learning and Machine Learning models for tweet sentiment analysis. I experimented with different values for hyperparameters such as learning rate, number of epochs, kernel size, etc. in the model exploration step.
- 1-D CNN
- First, I applied an embedding layer here the data is embedded to a length of 128.
- The data is then passed through three 1-D CNN layers with kernel sizes 3, 4, and 7 respectively. The stride used was
1 with 100 in/out channels. For this, I used
PyTorch’s Conv1d layer. - The output of the CNN layer is then passed through a ReLU activation function and maxpool-ed to reduce the complexity of the model.
- Finally, the data is flattened and passed through a fully connected layer to reduce the output size to 2 (denoting the positive and negative labels).
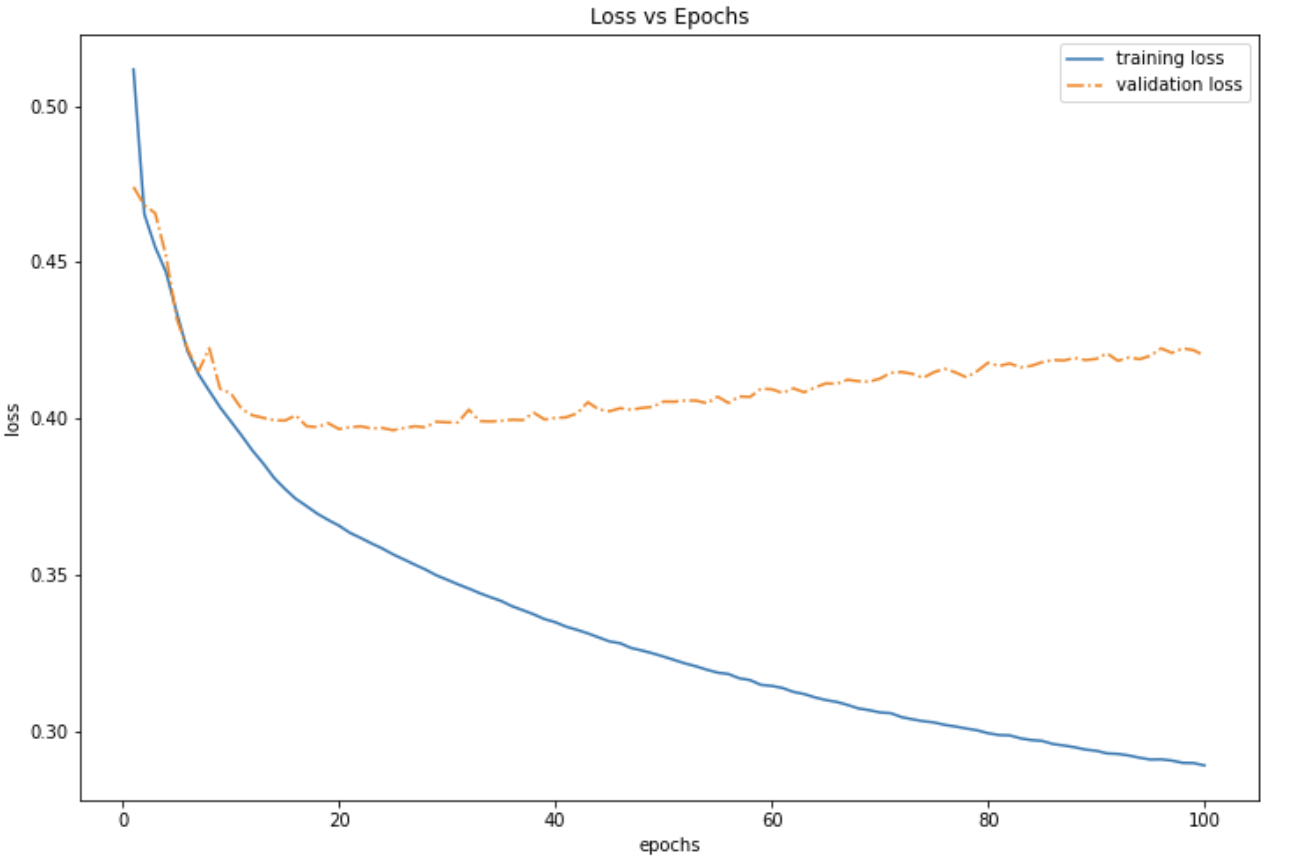
- The model was trained for 100 epochs with a learning rate of 0.0005.

- RNN
- Similar to the previous model, an embedding layer is applied where the data is embedded to a length of 128.
- The embeddings are passed through three RNN layers with input and hidden size of 64, and ReLU activation. For this, I used PyTorch’s RNN layer.
- The output of the RNN layer is then maxpool-ed to reduce the complexity of the model.
- Finally, the data is flattened and passed through a fully connected layer to reduce the output size to 2 (denoting the positive and negative labels).
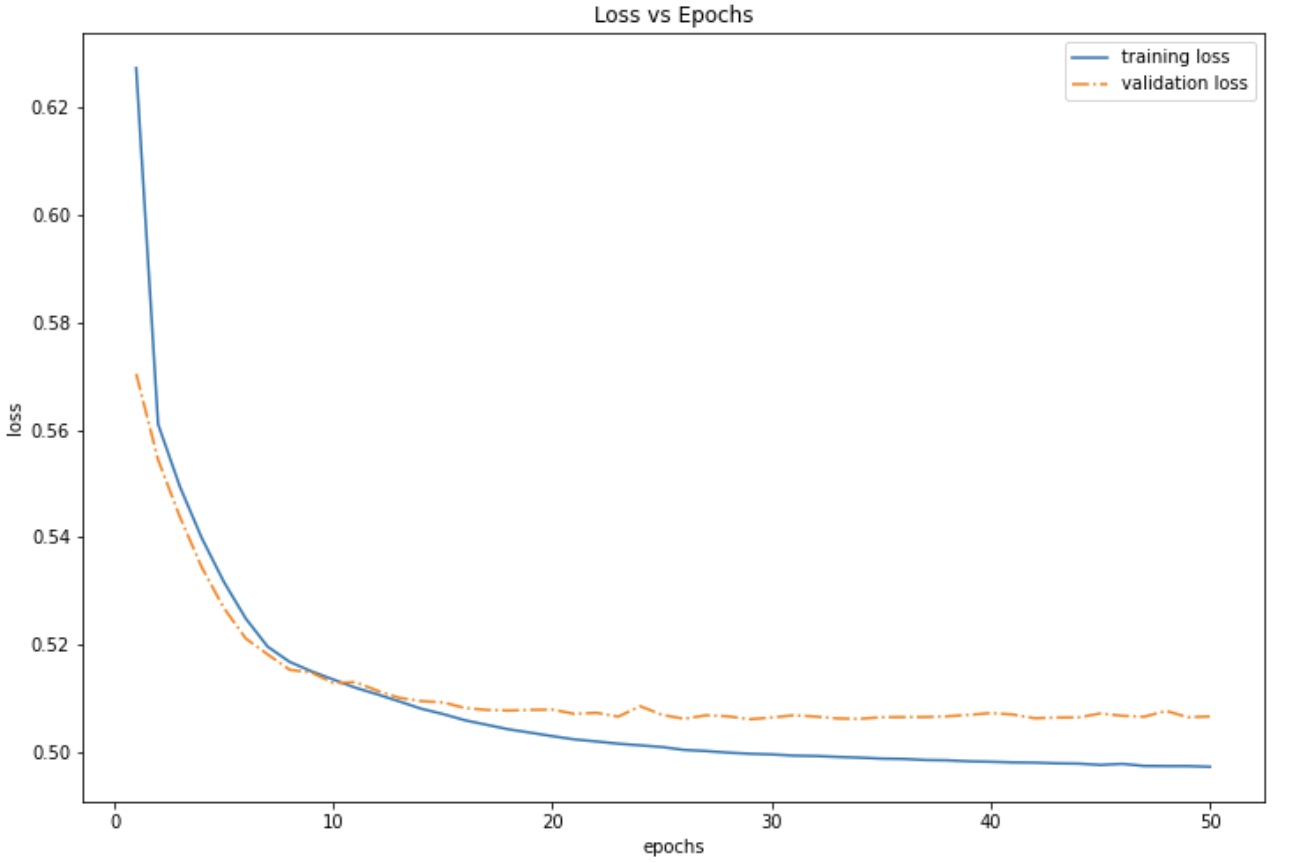
- The model was trained for 50 epochs with a learning rate of 0.0005.

- Logistic regression
- For this Machine Learning technique, I used the
sklearnlibrary’s LogisticRegression class. - First, I used the CountVectorizer class to extract the features from the text data. All words that were present in less than 5 different tweets were discarded by setting the min_df option to 5.
- Training and testing data sets were then transformed using this CountVectorizer and passed to the model.
- I set the maximum number of iterations to 10000 while training the model.
- Random Forest Classifier
- I used
sklearnlibrary’s RandomForestClassifier class to train the model. - I used the same preprocessed training and testing from the previous step.
- 100 estimators with a maximum depth of 5 and 5 minimum lead nodes were used,
- The parameters were determined by testing various scenarios of under- and over-fitting.
- Performance Validation
To compare the performance of all the models, I used an 80-20 train-test split of the dataset.
For CNN and RNN, an L2 regularization was used to prevent over-fitting and increase validation accuracy.
| Model | 1-D CNN | RNN | Logistic Regression | Random Forest Classifier |
|---|---|---|---|---|
| Accuracy | 82.24% | 79.85% | 79.73% | 77.64% |
What I learned
-
Importance of clean and sufficient data
The key takeaway for me from this project is the importance of clean and sufficient data while training a model.
Without cleaning the data, the same models perform extremely poorly. Also, while training the same models with only the first dataset, the highest accuracy achieved was 68%. This shows the importance of sufficient amount of data required to train these models. -
Hyperparameter tuning and their impact on under- and over-fitting
The above results were achieved after experimenting with the different values of various hyperparameters such as learning rate, kernel sizes, number of epochs, batch size, etc. I learned how to tune these hyperparameters while dealing with under- and over-fitting of data. -
PyTorch Library
I learned how to create Deep Learning models using PyTorch library and explored other PyTorch classes and functions. I learned how to write a Forward and a Backward pass for the models and how to evaluate the training and validation losses during training.
Finally, I also learned that CNNs also perform great while dealing with text data!